我们能获得推荐系统的大模型吗?
导读本次分享的主题是我们能获得推荐系统的大模型吗?具备“伸缩法则(Scaling Law)”是大语言模型(LLM)的典型特点,也就是说随着模型规模增大,模型效果持续增长。目前的推荐模型并不具备 Scaling Law 特性,模型的参数规模对效果影响有限。我们改进模型试图使得推荐模型也能具备“Scaling Law”这种大模型独具的特点。目前研究表明强大的知识记忆能力是 LLM 性能优异的主要原因之一,这启发我们在推荐模型中引入独立的记忆机制,用来存储、学习和记忆任意组合特征,本次分享将介绍这种记忆系统 HCNet,以及由此构造的MemoNet。我们发现引入独立记忆机制后,推荐模型初步表现出了 Scaling Law 特性。
本次分享会围绕四个方面展开:
1. 来自LLM的启示
2. HCNet & MemoNet:特征组合记忆机制
3.MemoNet 的效果
4. 总结与展望
分享嘉宾|张鹏涛博士
编辑整理|王晓霞
内容校对|李瑶
出品社区|DataFun
01
来自LLM的启示
首先介绍第一部分:来自LLM的启示。
1.大语言模型:快速发展
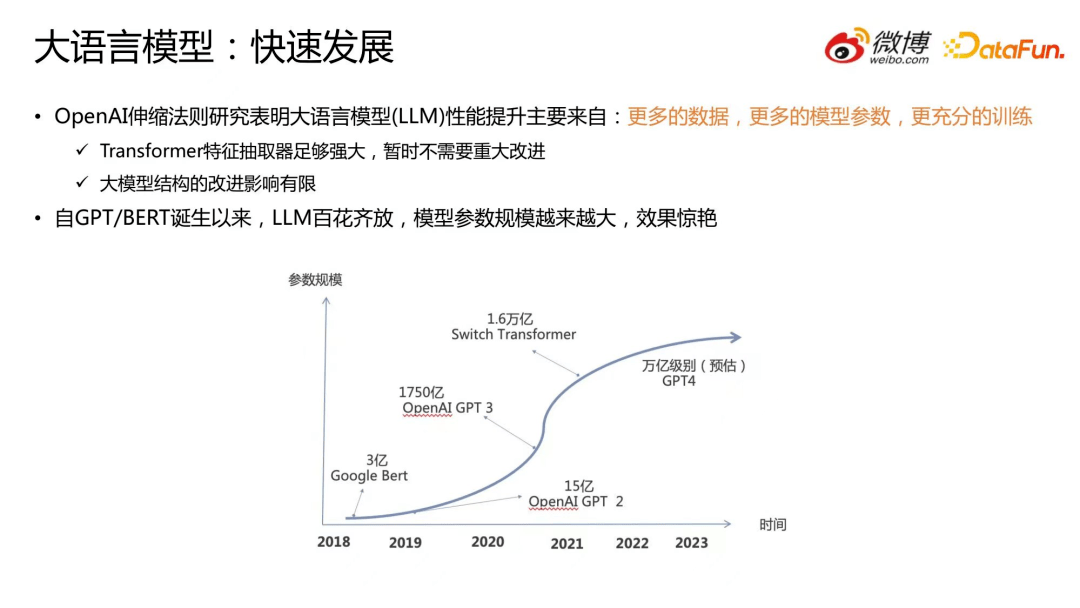
近几年来,大模型飞速发展,效果惊艳。OpenAI 伸缩法则研究表明大语言模型(LLM)性能的提升主要来自于三个方面:更多的数据、更多的模型参数、更充分的训练。当前研究表明:在特征抽取器方面,Transformer 性能足够强大,暂时不需要重大改进;大模型结构的改进对模型效果的影响有限。因此,大模型性能的提升更多的来自于上面所提及的数据、参数以及充分的训练。
我们可以看到,自GPT/BERT 诞生以来,大语言模型百花齐放,模型的参数规模越来越大,效果非常好。
2.大语言模型:大模型的典型特点
大语言模型有一个非常典型的特点:伸缩法则(Scaling Law)。所谓伸缩法则就是给定充足的训练数据,随着模型参数规模增大,模型效果持续增长。
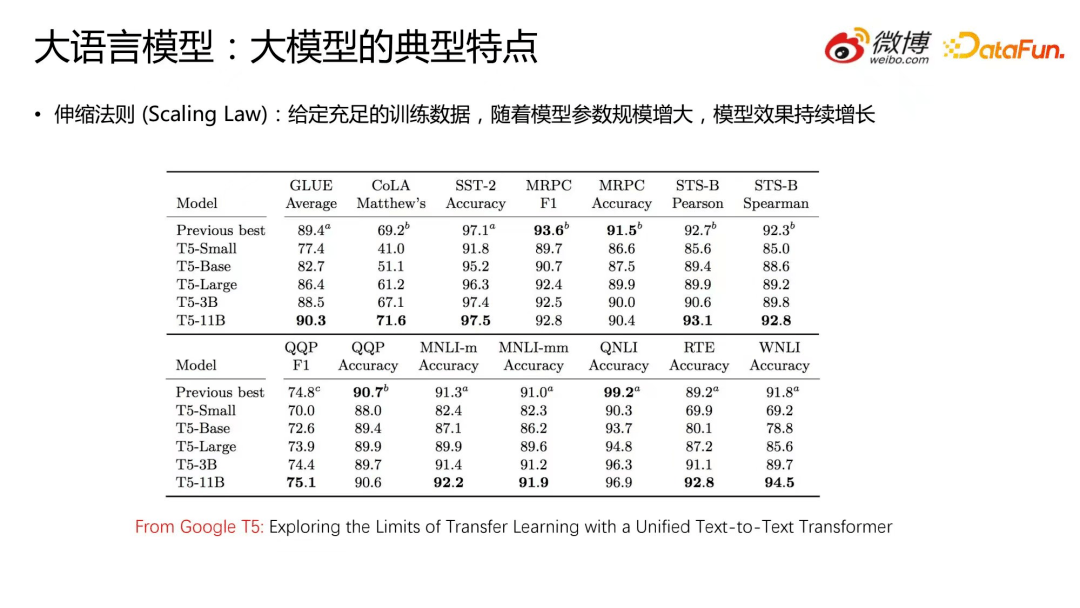
以Google T5中的一个图为例,我们可以看到,随着模型参数的增大,对应模型的效果单调上升,而且上升幅度比较大。
3.大模型的记忆能力:记忆与泛化
大模型效果为什么好?这里就需要提到大模型的记忆能力。今年 OpenAI 提出“压缩即智能”理论,即将 GPT 模型的训练过程看作对训练数据的无损压缩过程。之前很多研究也表明:大模型具备极强的记忆能力;模型规模越大,记忆能力越强;模型规模越大,效果越好,极大程度上来源于增强的记忆能力。
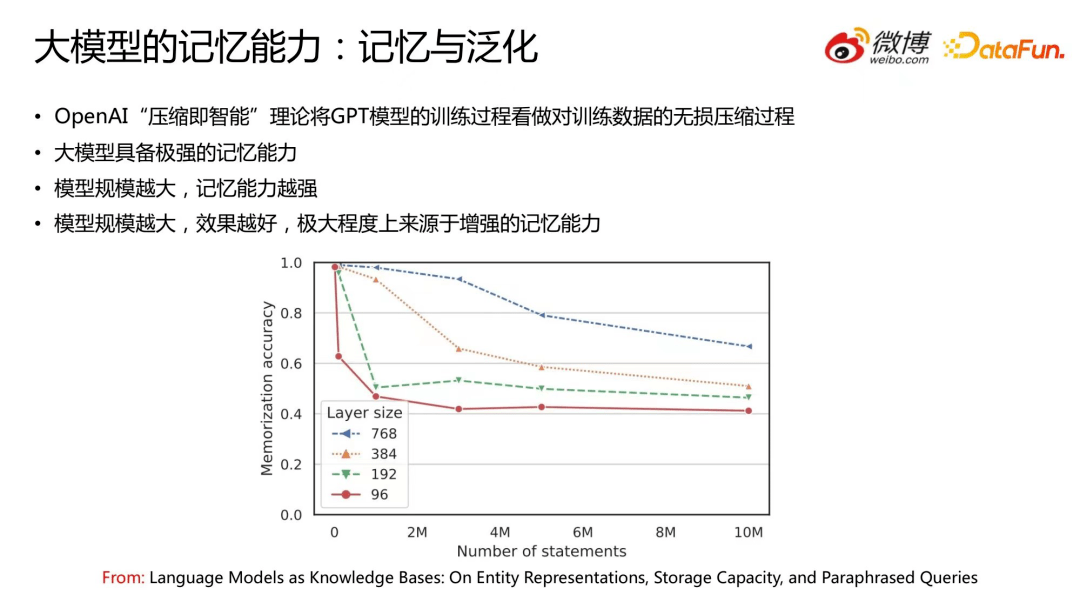
上图表明,相同的数据量,模型规模越大,对数据的记忆能力越强。
4.大模型的记忆能力:记忆位置在哪里
现在有很多对大模型记忆位置等记忆能力的研究,这里给出其中一篇论文《Transformer Feed-Forward Layers Are Key-Value Memories》所提供的解释。该论文认为 Transformer 的知识记在 FFN 里,FFN 本质上是一个 Key-Value 数据库。但现在有最新研究表明,在 Transformer 的 Attention 机制中实际上也存在知识的存储。
5.推荐模型的现状
我们现在来看一下推荐模型的现状。
推荐模型是过参数化的,所谓过参数化就是参数规模远远大于模型本身所需要的参数量。很多模型引入了 UID,MID 等 ID 类特征,其模型的参数规模远远大于训练样本的规模,这其实是过参数化的。在过参数化的情况下,进一步增大模型的参数规模对效果的影响是有限的。由此可以得出结论,目前的推荐模型不具备 Scaling Law 特性,即模型效果不会随着模型参数规模的增大而持续上升。举一个例子来说明。
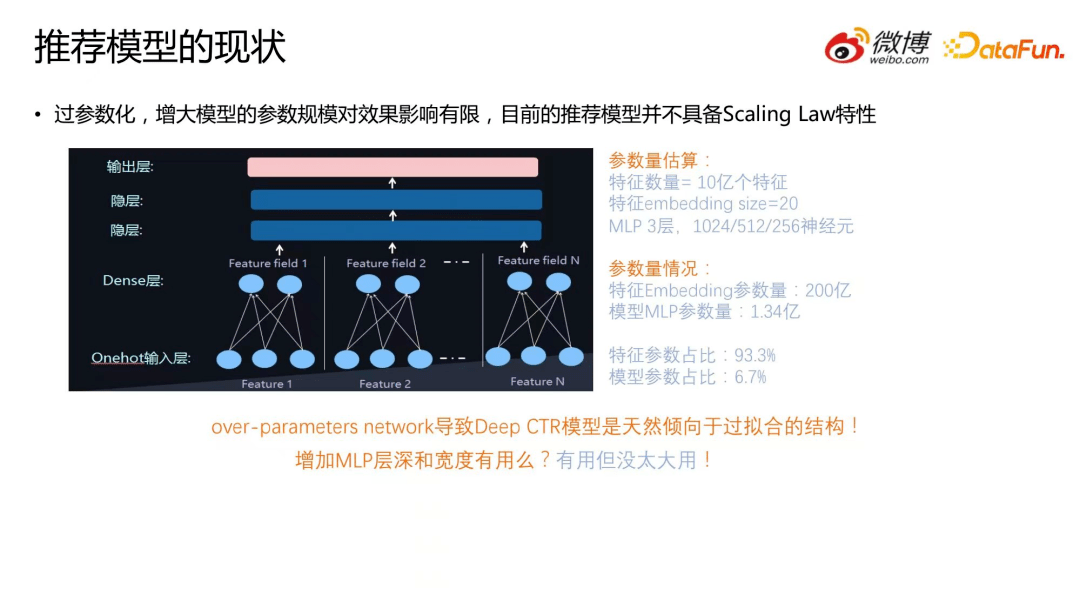
首先做参数量估算。假设我们构建一个基础的模型,其中有10亿个 ID 类特征,每个特征的 embedding size 为20,后面接三层的 MLP,对应的神经元个数分别为 1024,512,256。那么在做参数量估算的过程中,我们发现特征 embedding 参数量有 200 亿,模型 MLP 参数量有 1.34 亿。由此可以看出,这个推荐模型的参数量主要集中在 embedding 层,占比为 93.3%。在这种情况下,如果继续增加特征的 embedding size 能够获得的效果收益其实是有限的,它并不会随着 embedding size 的增加而单调上升。那么增加 MLP 层的深度和宽度有用吗?答案是有用但没太大用。有些场景下有用,但是并没有表现出 Scaling Law 的特性。
目前推荐模型的过参数化的网络天然倾向于过拟合的结构,即增加参数量对效果的影响有限。
那么,我们能获得推荐领域的大模型吗?
结合上下文的思考,我们希望通过改进推荐模型,试图使得推荐模型具备Scaling Law 这种大模型独具的特点。
6.增强推荐模型的记忆能力:学习并记住所有特征组合的表示
受大模型 Scaling Law 的特性和记忆机制的启发,我们希望能够增强推荐模型的记忆能力,让模型学习并记住所有特征组合的表示。我们的做法是在推荐模型中引入独立的记忆机制,用来存储、学习、记忆任意特征组合。我们希望增大记忆机制的参数规模能够持续提升模型效果,让推荐模型表现出 Scaling Law 特性。我们提出的模型整体结构如下图。
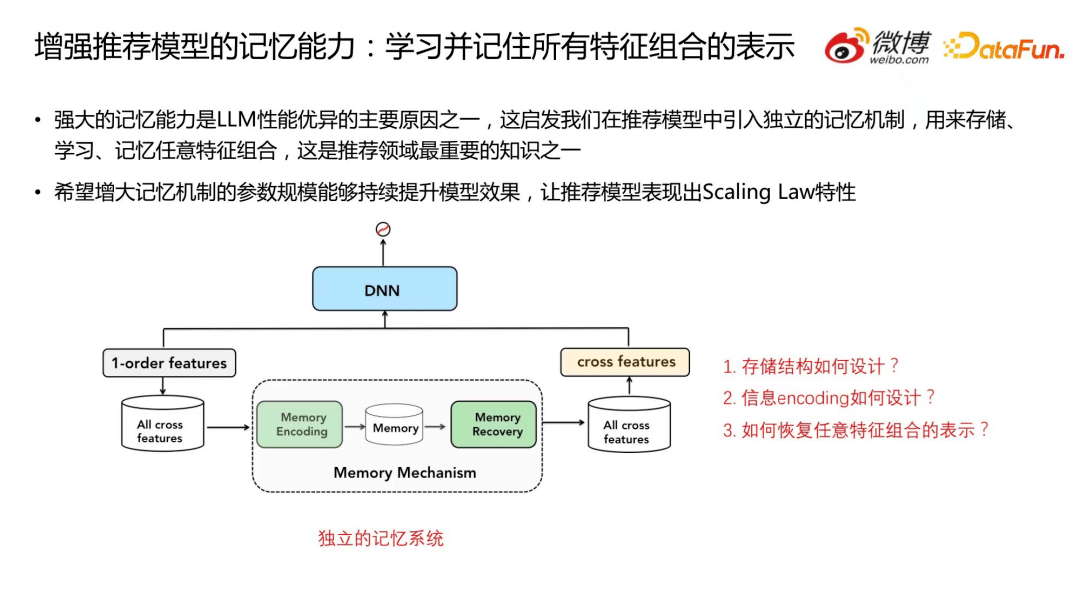
通常情况下,一个典型的 CTR 预估模型就是将一阶特征 1-order features 直接输入到 DNN 中。而在本方法中,我们还通过一阶特征构建了所有组合特征,存入独立的记忆系统,然后从记忆系统里面把所有组合特征的 embedding 恢复出来再输入到 DNN 中,那么 DNN 的输入就由原来的一阶特征变成了一阶特征+组合特征。
这里的核心挑战是如何设计独立的记忆系统。这需要解决如下几个问题:存储结构(Memory)如何设计?信息编码(Memory Encoding)如何设计?如何恢复任意特征组合的表示(Memory Recovery)?
接下来我们会详细回答这些问题。
7.和现有模型的差异
我们提出的这种结构和现有模型存在哪些差异?接下来对比几种模型范式。
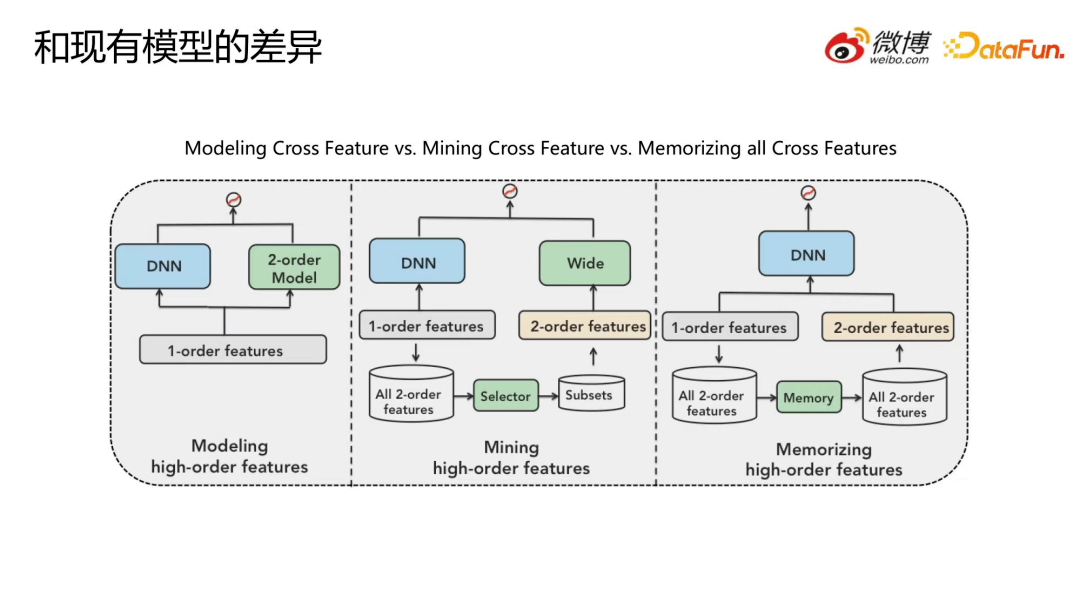
如上图,第一种是 Modeling high-order features,输入一阶特征 1-order features,分别送入 DNN 和 2-order model 子网络做建模,其中最典型的模型代表是 DeepFM。
第二种是 Mining high-order features , 从一阶特征构造出所有的二阶特征组合,然后选出很少的特征组合构成特征组合子集,为子集中的每个组合特征值分配 embedding,之后送入 wide 部分。这类模型的典型代表是Wide&Deep。
第三种是 Memorizing high-order features, 即记忆所有的组合特征,并且能恢复回去,提取出二阶特征 embedding 之后送入 DNN 中。与之前模型范式最大的不同是我们提出的方法能够记忆所有的高阶组合特征。
02
HCNet & MemoNet: 特征组合记忆机制
第二部分主要介绍:特征组合记忆系统 HCNet,以及由此构造的 CTR 预估模型 MemoNet,详细解析特征组合记忆机制。
1. HCNet & MemoNet
我们希望利用一个简单的方案来验证推荐大模型是否能展现出 Scaling Law特性。方案需要满足以下两个要求:
(1)用尽量少的参数获得好的效果;
(2)增大模型参数规模能持续提升模型效果。
我们的这项工作已整理成论文《MemoNet: Memorizing All Cross Features' Representations Efficiently via Multi-Hash Codebook Network for CTR Prediction》,并已在 CIKM2023 发表(https://dl.acm.org/doi/10.1145/3583780.3614963),模型源码已经上传至 GitHub ,地址:https://github.com/ptzhangAlg/RecAlg。
2.MemoNet:整体结构
接下来看一下 MemoNet 的整体结构。
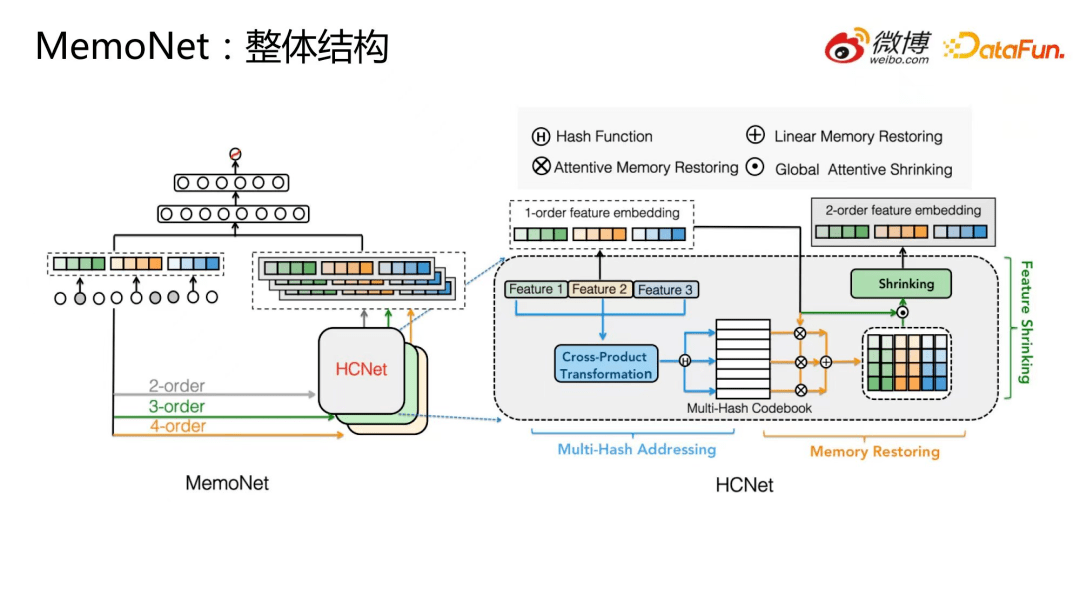
MemoNet 结构如上图左侧所示,通过一阶特征分别构建二阶、三阶、四阶组合特征,输入到 HCNet,HCNet 会分别返回二阶、三阶、四阶特征组合的 embedding(其数量与一阶特征一致),然后将一阶特征 embedding 与其进行 concat,输入到 DNN。从中可以看出,我们所引入的 HCNet 是一个独立模块,它可以很方便地嵌入到不同的 CTR 预估模型中。
3.HCNet:整体结构
下面是 HCNet 的整体结构。
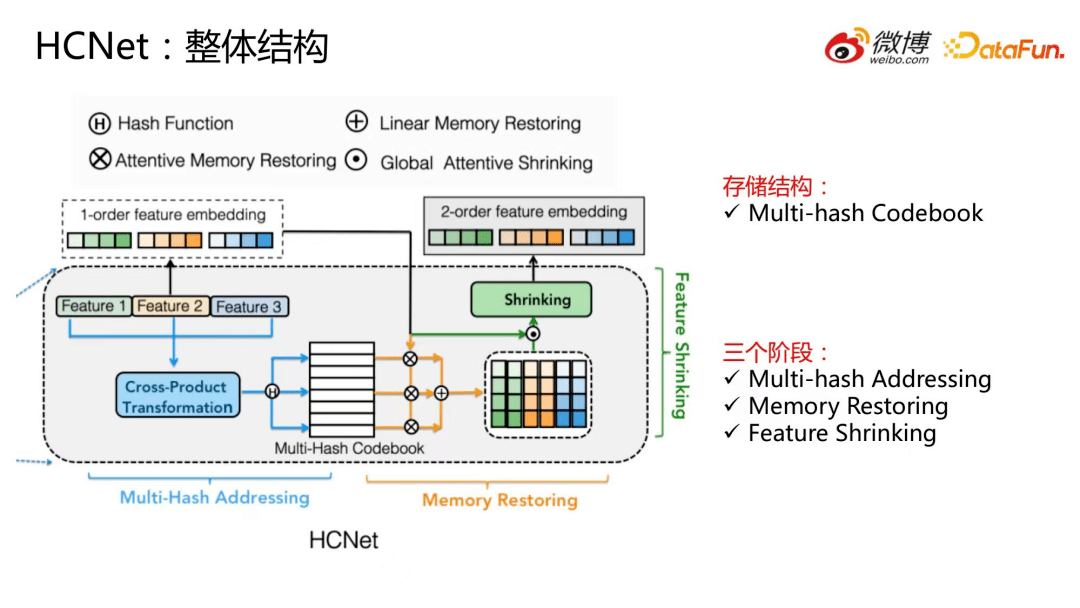
首先,一阶特征通过特征转化(Cross-Product Transformation)构造出所有特征组合,每个特征组合分别进行多哈希寻址,定位其对应的 codeword 的位置。然后,基于多哈希寻址结果取出对应的 codeword(即embedding),进一步对多个 codeword embedding 进行拼接、转化,完成记忆恢复,得到特征组合的 embedding 表示。最后,为了解决特征组合爆炸的问题,我们进行了组合特征压缩,将输出组合特征的数量压缩至一阶特征数量。接下来将分别介绍 HCNet 的存储部分 Multi-Hash Codebook 以及三个处理阶段:多哈希寻址、记忆恢复、特征压缩。
4.Multi-Hash Codebook
首先来介绍 Multi-Hash Codebook。Codebook 就是知识(所有的特征组合)存储的地方。一个 Codebook 由很多 codeword 组成,codeword 是最基础的记忆单元,简单来说,是一个向量。Codebook 采用 embedding table 的高效实现。多哈希寻址之后只需要对 Codebook 做 lookup ,就能取出对应的 codeword。
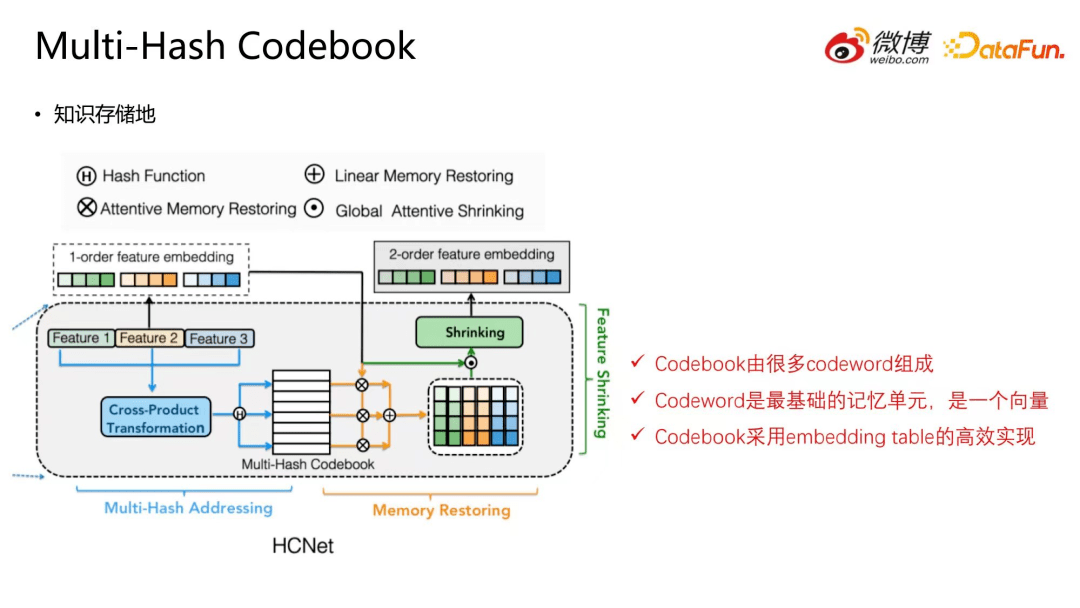
5.第一阶段:Multi-hash Addressing
Multi-hash Addressing,即多哈希寻址,主要是指从实例的特征构造特征组合,并利用多哈希寻址,定位每个特征组合对应的 codeword。

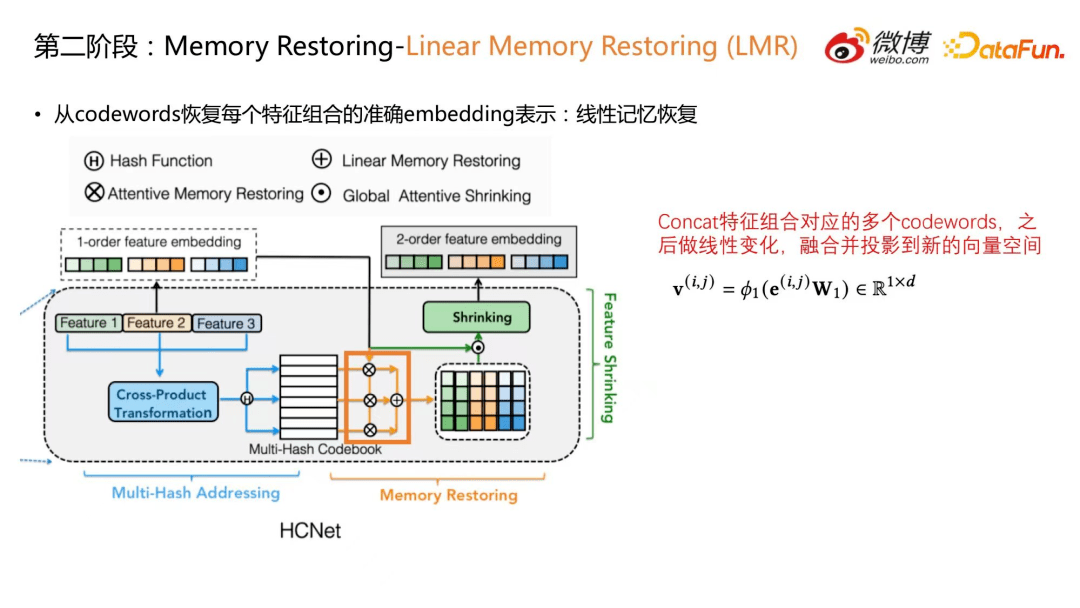
6.第二阶段:Memory Restoring-Linear Memory Restoring (LMR)
Memory Restoring,即记忆恢复,从 codeword 中恢复每个特征组合的准确 embedding 表示。本文提供两种记忆恢复机制,一种是线性记忆恢复(Linear Memory Restoring,LMR),如下图,通过对特征组合对应的多个 codeword 进行 concat,再做线性变化,融合并投影到新的向量空间。
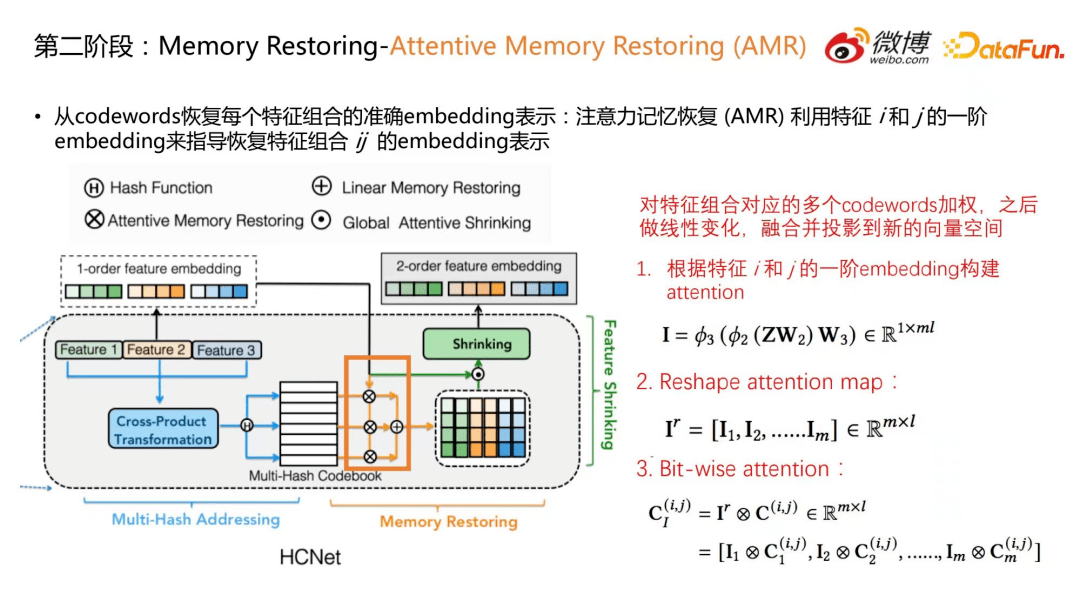
7.第二阶段:Memory Restoring-Attentive Memory Restoring (AMR)
第二种记忆恢复机制是基于注意力的记忆恢复。基于注意力的记忆恢复 (Attentive Memory Restoring, AMR) 利用特征 i 和 j 的一阶 embedding 来指导恢复特征组合 ij 的 embedding 表示。
主要是通过对特征组合对应的多个 codeword 进行加权,再做线性变化,融合并投影到新的向量空间。
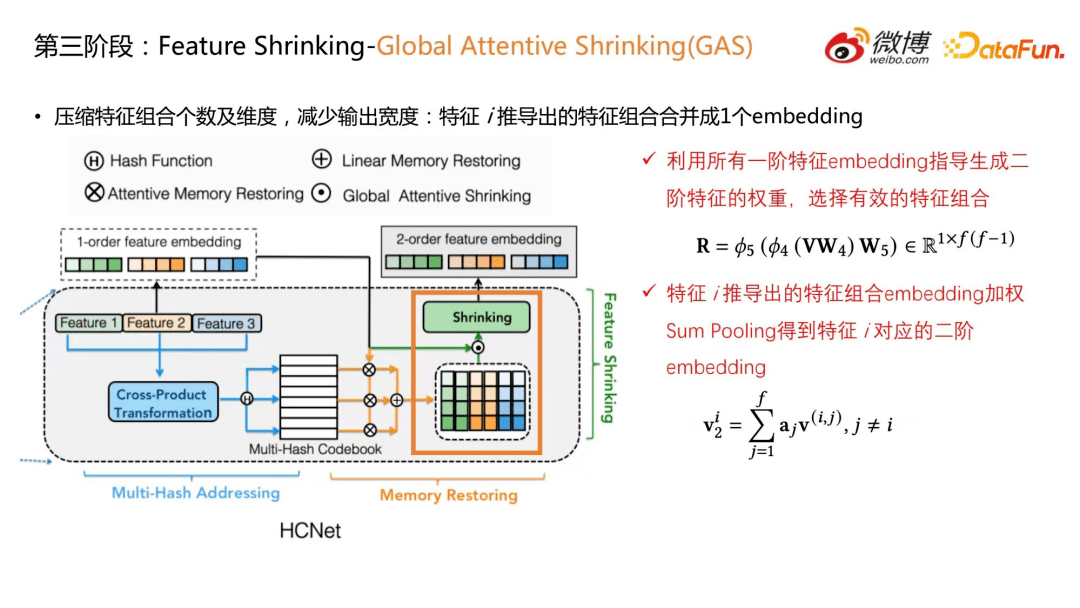
8.第三阶段:Feature Shrinking-Global Attentive Shrinking(GAS)
为了解决特征组合爆炸的问题,HCNet 引入特征压缩阶段。这里主要介绍全局 attention 的压缩方式。这个阶段的主要目的是压缩特征组合个数及维度,减少组合特征的输出宽度,做法是将特征 I 推导出的特征组合合并成一个 embedding。一个特征 I 只对应一个二阶特征 embedding,那么得到的二阶特征 embedding 数量和一阶特征 embedding 是一样的。
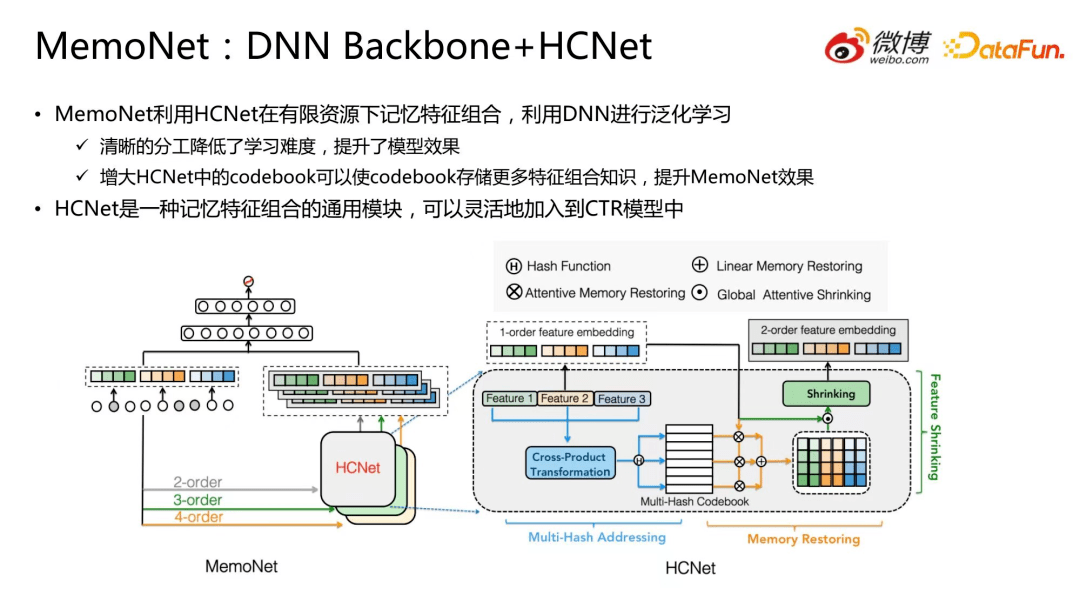
9.MemoNet:DNN Backbone+HCNet
HCNet 是一种记忆特征组合的通用模块,可以灵活地加入到 CTR 模型中。
为了验证记忆机制的效果,我们把 HCNet 和 DNN 做了简单结合,由此提出了 MemoNet。
MemoNet 利用 HCNet 在有限资源下记忆特征组合,利用 DNN 进行泛化学习。
清晰的分工降低了学习难度,提升了模型效果
增大 HCNet 中的 codebook 可以使 codebook 存储更多特征组合知识,提升 MemoNet 效果
清晰的分工降低了学习难度,提升了模型效果
增大 HCNet 中的 codebook 可以使 codebook 存储更多特征组合知识,提升 MemoNet 效果
10.关键特征(Key Interaction Field, KIF)
我们在实验过程中发现,构造所有的特征组合本身是一个耗时、耗资源的过程。特征组合数量爆炸,该如何平衡效率和效果呢?首先我们提出以下假设:
只有少量关键特征 (Field) 对于特征组合是重要的;
只使用关键特征的特征组合可以很好地平衡效率和效果。
只有少量关键特征 (Field) 对于特征组合是重要的;
只使用关键特征的特征组合可以很好地平衡效率和效果。
那么,怎么找出关键特征呢?
Feature Number Ranking (FNR):根据特征的特征值个数倒排,选择 Top K 个特征
Field Attention Ranking (FAR):训练好 HCNet 之后,在一个小型验证集上,累计某个特征对应的所有特征组合的GAS 注意力权重,作为特征重要性指标,选择 Top K 个特征
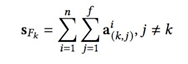
Feature Number Ranking (FNR):根据特征的特征值个数倒排,选择 Top K 个特征
Field Attention Ranking (FAR):训练好 HCNet 之后,在一个小型验证集上,累计某个特征对应的所有特征组合的GAS 注意力权重,作为特征重要性指标,选择 Top K 个特征
03
MemoNet的效果
1.效果对比
接下来我们看一下 MemoNet 的效果,如下图所示:
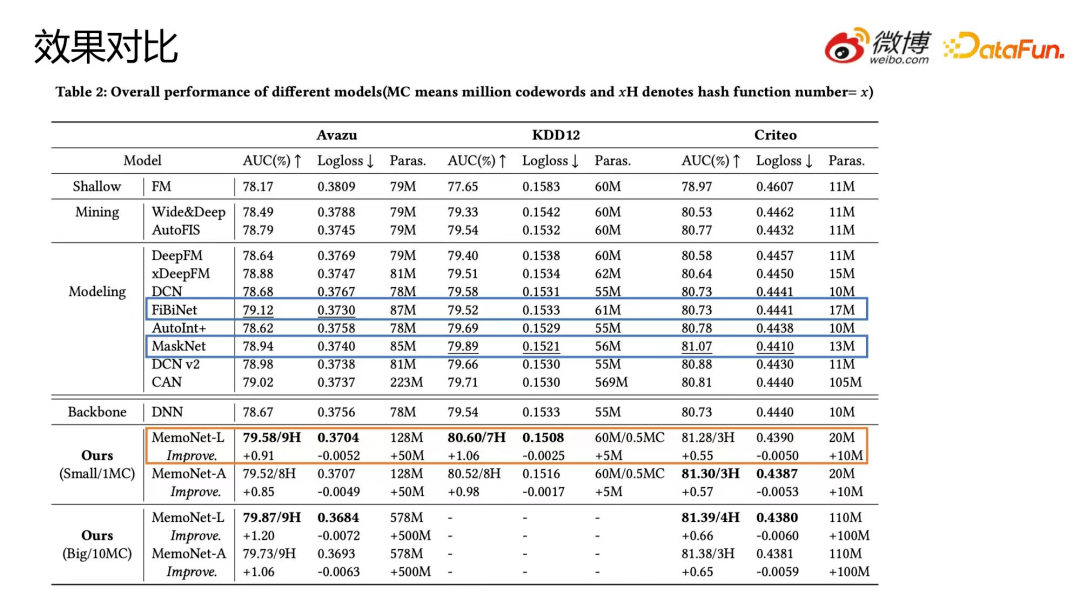
首先看一下 baseline 模型情况,在 Avazu 数据集中训练效果最好的模型 FiBiNet AUC 为 79.12,在 KDD12 数据集中效果最好的模型 MaskNet AUC 为 79.89,在 Criteo 数据集上训练效果最好的模型 MaskNet AUC 为 81.07。
再来看我们的 MemoNet-L 的表现,Avazu 上 AUC 达到了 79.58,KDD12上AUC 达到了 80.60,而Criteo 上 AUC 也达到了 81.31,相较于 baseline 的提升是比较大的。再把 codeword 数提升到一千万,从最后一栏MemoNet (big) 可以观察到模型的效果再次得到了显著提升。

2.Codeword数量的影响:Scaling Law
通过 codeword 数量的变化观察模型是否具有 Scaling Law 特性,从下图可以看出,当 Codeword 数量从 1 万逐步增加至 1 亿:在 Avazu 和 Criteo 上,模型效果稳步上升,而在 KDD12 上,模型效果先升后降,当 codeword 数量为 0.5M 时效果最好,这可能是因为 KDD12 上有效的组合特征数量较少。
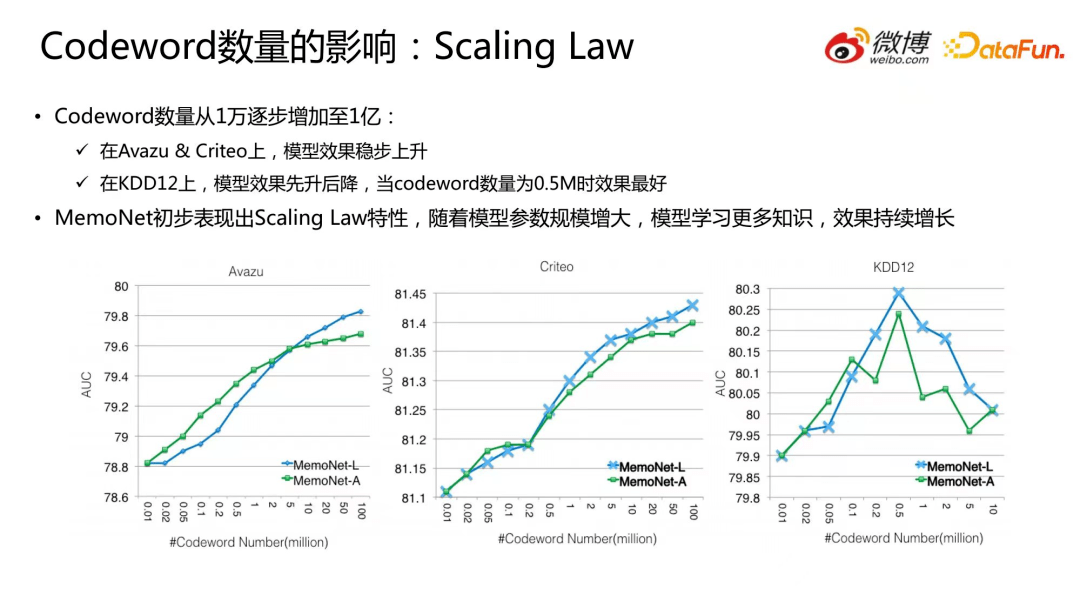
从实验可以得出 MemoNet 初步表现出了 Scaling Law 特性,随着模型参数规模增大,模型学习更多知识,效果持续增长。
3.记忆恢复策略对比:LMR vs AMR
在上图中也可以看到,线性的记忆恢复 LMR 和基于 Attention 机制的记忆恢复这两种策略,在 codeword 数量少时, AMR 策略效果更好;当 codeword 数量多时, LMR 占优。当 codeword 数量少时,更多的特征组合共享一个 codeword,attention 机制有助于恢复特征组合的表示。
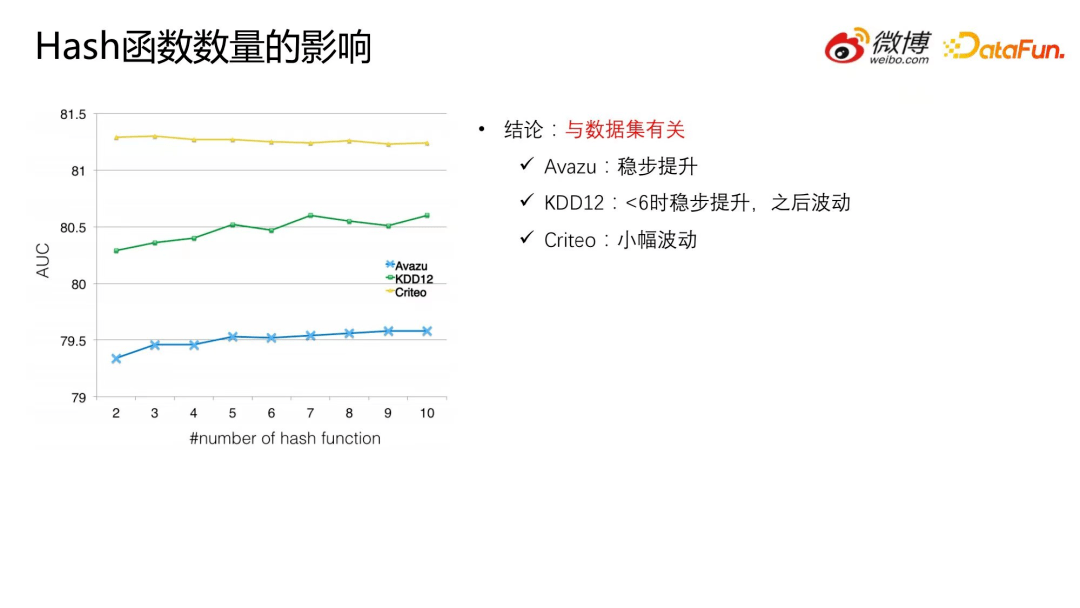
4.Hash函数数量的影响
从整体上看, hash 函数数量增多使得模型表现更好,从如下图的实验结果来看,hash 函数数量对模型性能的影响与数据集有关。具体的,在Avazu 数据集上随着 hash 函数数量增多,效果稳步提升;在KDD12 上整体趋势是稳步提升的,之后有波动;在Criteo 数据集上 hash 函数数量影响不大,呈小幅波动状态。
5.HCNet作为SOTA模型的插件
从如下图中可以看出,将 HCNet 嵌入多个 CTR 预估模型之后,所有模型在三个数据集上效果都有很大提升。其中MaskNet + HCNet 效果最好。这启发我们去探索是否有更好的基于HCNet 的特征组合建模方式。

6.关键特征识别方法效果
接下来是关键特征识别方法的对比。
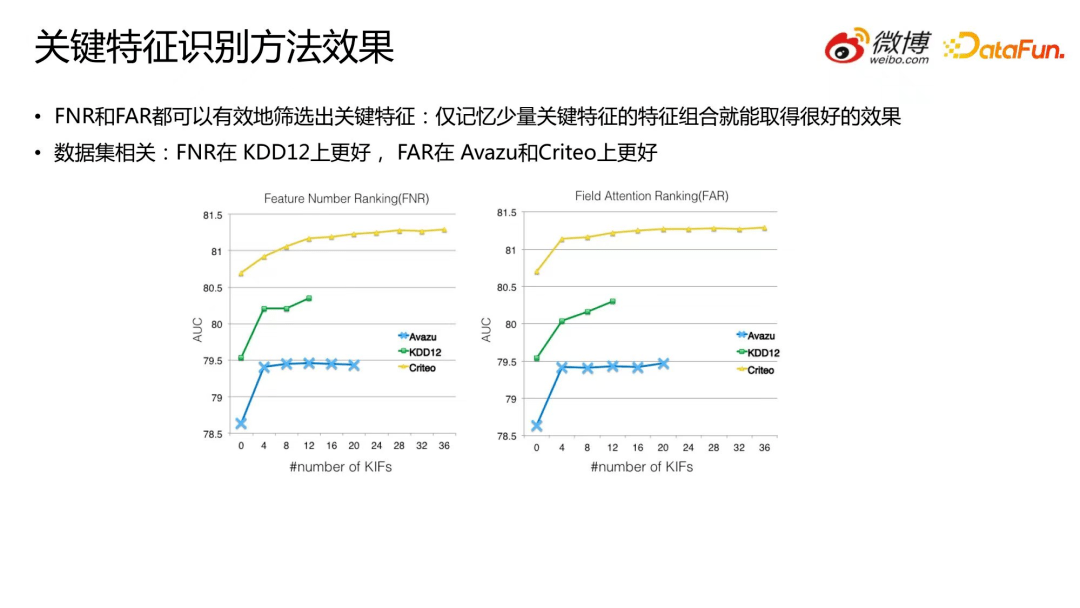
从上图中我们可以很清晰地看到,未引入 HCNet 时 DNN 模型在Avazu数据集上 AUC 为 78.5,在加入四个关键特征后MemoNet 效果大幅提升。FNR 和 FAR 都可以有效地筛选出关键特征,仅记忆少量关键特征的特征组合就能获得记忆组合特征的大部分收益。不同的关键特征识别方法对MemoNet 效果的影响是数据集相关的:FNR 在 KDD12 上效果更好, FAR 在Avazu 和 Criteo 上效果更好。
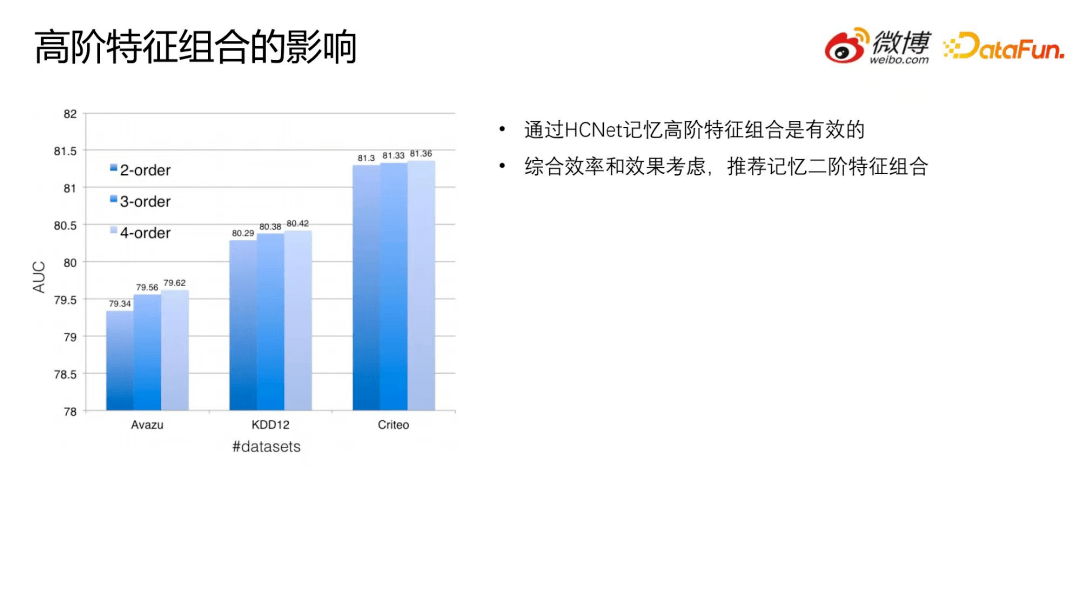
7.高阶特征组合的影响
对比高阶特征组合的影响,可以看出,通过 HCNet 记忆高阶特征组合是有效的。但是综合效率和效果考虑,推荐记忆二阶特征组合。
8.线上实验
线上实验方案是将 HCNet 作为插件加入到线上排序模型来做 AB 测试。效果是实验组的 CTR 有 9.73% 的提升,用户时长提升了 6.86%。在效率上,使用 Top 4 关键特征,线上响应延迟降低了 10.33%。
04
总结与展望
最后来做一下总结和展望。
HCNet 实现了一种独立高效的记忆机制,利用有限资源存储、学习和记忆任意特征组合,可以灵活地加入到 CTR 模型中。
MemoNet 初步表现出 Scaling Law 特性,随着模型参数规模增大,模型效果持续性提升。
HCNet 实现了一种独立高效的记忆机制,利用有限资源存储、学习和记忆任意特征组合,可以灵活地加入到 CTR 模型中。
MemoNet 初步表现出 Scaling Law 特性,随着模型参数规模增大,模型效果持续性提升。
后续研究方向包括:
探索更加高效的记忆机制,记忆更多知识。
探索适配的特征组合建模机制。
探索更加高效的记忆机制,记忆更多知识。
探索适配的特征组合建模机制。
以上就是本次分享的内容,谢谢大家。

分享嘉宾
INTRODUCTION
张鹏涛 博士
北京大学计算机应用博士,原新浪微博技术专家,发表多篇机器学习相关论文,关注领域包括大语言模型、个性化推荐系统、企业数字化转型等领域。
往期优质文章推荐
往期推荐
AIGC与大模型赋能机器人智能控制
百度凤巢大模型与搜索广告满意度设计与实践
如何应对大数据量挑战?分布式事务型 KV 数据库 TiKV 的实现和实践
当大语言模型遇见推荐系统
一个范式了解通用人工智能的进化!神经网络大模型 ⊕ 知识图谱 ⊕ 强化学习 = AGI
懂数据才能搞好业务,数据平台在Qunar的精细化运营中如何实现业务增值?
蚂蚁金融事理图谱构建及应用
快手3D数字人直播互动解决方案
数据服务化在京东的实践 返回搜狐,查看更多
责任编辑: